Identifying Land Features from Aerial Video/Images with Deep Learning
-
I recently got the idea that if a drone can identify the environment it's flying over, it can both find a safe landing area and create safe flight paths. And with the advances in deep learning, recognizing the environment from the camera feed is easier than ever.
Basically I needed to create an image classifier which works with various types of land features. To build this, I first needed a lot of labeled aerial images. To get started, I downloaded about 30,000 map tiles, 128x128px squares. But in order to train a model, they have to be labeled correctly. How do you label 30,000 tiny images?
First, I went through the entire folder, and moved obvious pictures into corresponding folder. The classes I decided on are: residential, commercial, play, brush, trees, field, road, parking, water, grass, sand and rocks. Since the map tiles I downloaded (using a Python script) were from a rectangular area, they were loosely grouped, so I was able to grab chunks of 10-15 from grassy areas, fields, residential areas. Took less than half hour to label about 1,000 images. Then I fed them into the model and trained it. I ran the trained model over the remaining 29,000 images, and classified them if there was a 80%+ certainty. Having the newly classified images in separate folders, I did a quick visual test, to remove those that were incorrectly classified. This time, I had 11,000 more images,bringing the total to 12,000. I repeated the process again, ending up with about 20,000 labeled images, which is a decent number to start with. Once I decide on a good training set, I will also perform data augmentation, but taking each map tile, rotating it 90, 180 and 270 degrees, and then also mirroring it horizontally and vertically. This will multiply the dataset 5-fold. Another step to take is to grab random tiles from the map (not just a specific area), to increase the variety of the training set, but that basic visual labeling will be much harder, since the tiles won't be grouped.
Now let's get to the actual image classifier. My software is written in Python, using Tensorflow as a deep learning framework. Tensorflow comes with the Inception v3 model already trained, which makes image classifying much easier. Inception is a 19-layer convolutional neural network, which was created to classify the ImageNet project. It's currently the gold standard in machine learning for imaging.
To train on my own set of images, I used transfer learning, which takes a model already trained for a problem and retrains it for a similar challenge. Whenever you want to classify images, Inception works perfectly. Training the whole model can take a lot of time (days or weeks, unless you have access to a lot of parallel processors). What we do with retraining is taking just the final layer, the one that does the classification into classes, and training it to differentiate between our images. So all I had to do was to put all the images in folders names according to my desired classes, and run a few lines of code. The entire process is well described on the Tensorflow website or here.
The trainer reports a final accuracy of 93%, which is quite amazing, even if it's on the training set. I ran it with some of the unclassified images, and I got over 80% precision, which is extremely good. And that was in the very beginning, before growing my training set. After adding more images and doing data augmentation, this will definitely increase.
So how do I use this? My first test was to display an aerial map (using OpenCV), and use the mouse to identify the small area where I clicked. As you can see below, I had a pretty much 100% success rate!

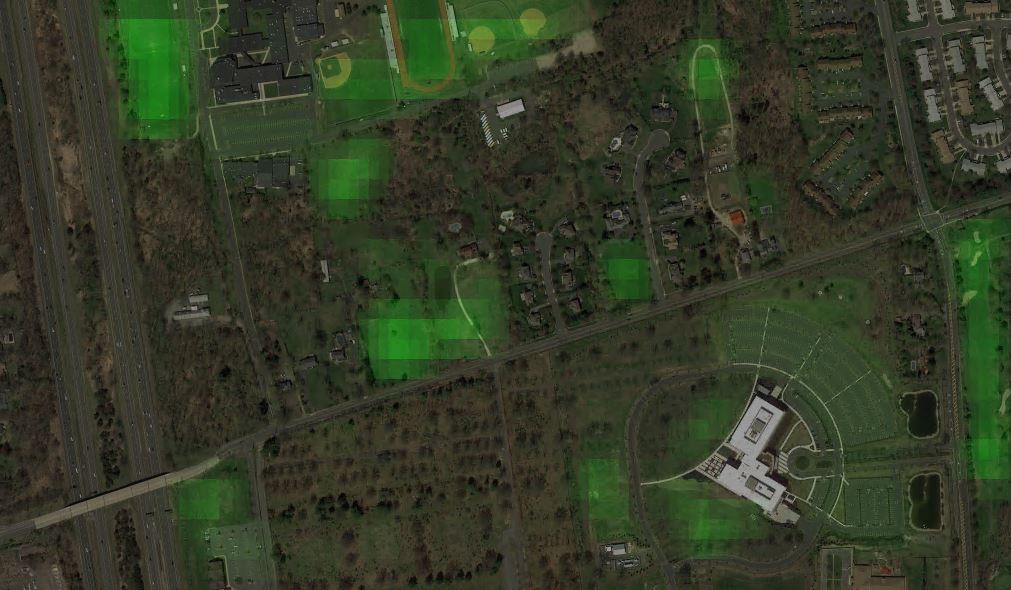
Another visualization was to take the same map, scan it, and create a heat map of safe landing areas for a drone. To do this, I had to define and prioritize what a landing areas is. At the top it's "grass", of course, with lower weights for "field" or "play" (which is tennis courts, baseball fields, etc) and even lower for "parking". The resulting heat map is below. It correctly highlights grassy areas, and colors the recreational area and big parking lots:
Getting back to how I recognize the images, Tensorflow makes it really easy, just initialize the graph that was trained before, feed it a JPG image, get the top results (or just the first), and display the results (together with a score - how sure the algorithm is of its answer). This is all the code you run for the inference:
image_data = tf.gfile.FastGFile(image_path, 'rb').read()
label_lines = [line.rstrip() for line
in tf.gfile.GFile("tf_files/retrained_labels.txt")]
with tf.gfile.FastGFile("tf_files/retrained_graph.pb", 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('final_result:0')
predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data})
Now the question remains... Would this model be able to identify images taken from the drone camera? I used map tiles for training, and the camera feed might look completely different. Ideally, I should train on actual drone video, but that would mean flying it a lot, and over a lot of varied terrain. Since that's not feasible right now, the best option would be to pre-process the camera frames so they look more like the standard satellite maps. But until then, I did a test on pre-recorded aerial footage from YouTube. Keep in mind that the model is still in very early stages, and there no processing of the aerial video. I'd say the results are pretty good. The confusion between residential/commercial comes from the fact that the model distinguishes those based on building size. The drone software would use the height and camera parameters to determine the actual size of the ground image, and scale it so it matches the training images.
So what's next? I mean, besides improving and tuning the classifier? Well, mainly building the drone software. Right now, my drone is based on a Raspberry Pi, which doesn't have the horse power to do real-time inference. My choice would be the Jetson TX-1 from Nvidia, a small embedded board with GPU capabilities for deep learning. I know rebuilding the drone around that would be a challenge, but I like challenges!
Get updates